Note: This article is outdated. Previously, because pandoc doesn’t support non-ASCII identifiers, rmarkdown adds the +ascii_identifiers extension by default. As pandoc now supports it and rmarkdown no longer addes the extension, the issue gets resolved.
Generally, the rmarkdown package supports non-ASCII strings very well, e.g., the link on the table of content works even for pure non-ASCII headers. However, I was bitten when using non-ASCII headers with the nice tabbed sections feature recently. Luckily, I found the solution rstudio/rmarkdown#1149 quickly, which I’d like to share to you.
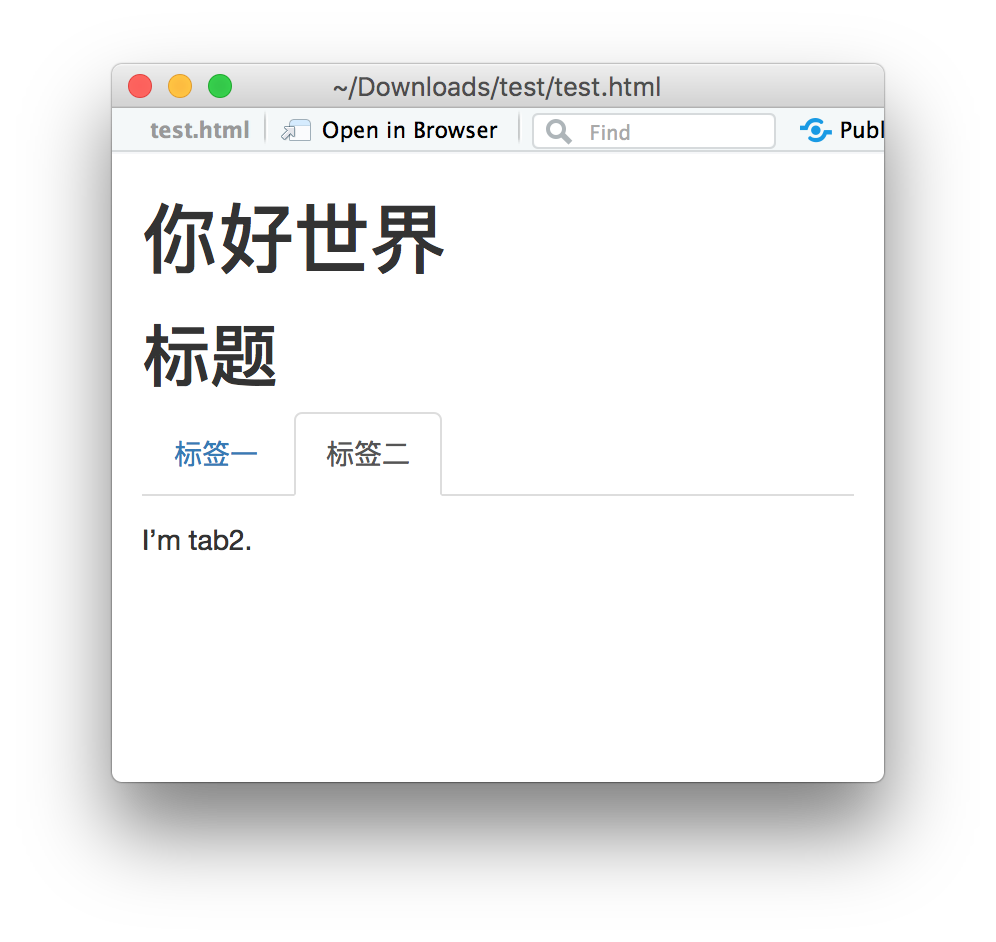
The problem is that if the headers below {.tabset} contain non-ASCII characters, the produced html page may not display the tabbed sections or the tabbed sections display the wrong content (e.g., always display the content of the tab1). Here’s a simple example (stolen from rstudio/rmarkdown#1149) :
---
title: 你好世界
output: html_document
---
# 标题 {.tabset}
## 标签一
I'm tab1.
## 标签二
I'm tab2.
There’re two simple solutions to fix it:
- Add an ASCII id mannuall,
- Or, remove the
ascii_identifiersextention by addingmd_extensions: -ascii_identifiersto the YAML header of your rmarkdown file (not sure if there’s any side-effects because I don’t know why it’s enabled by default).
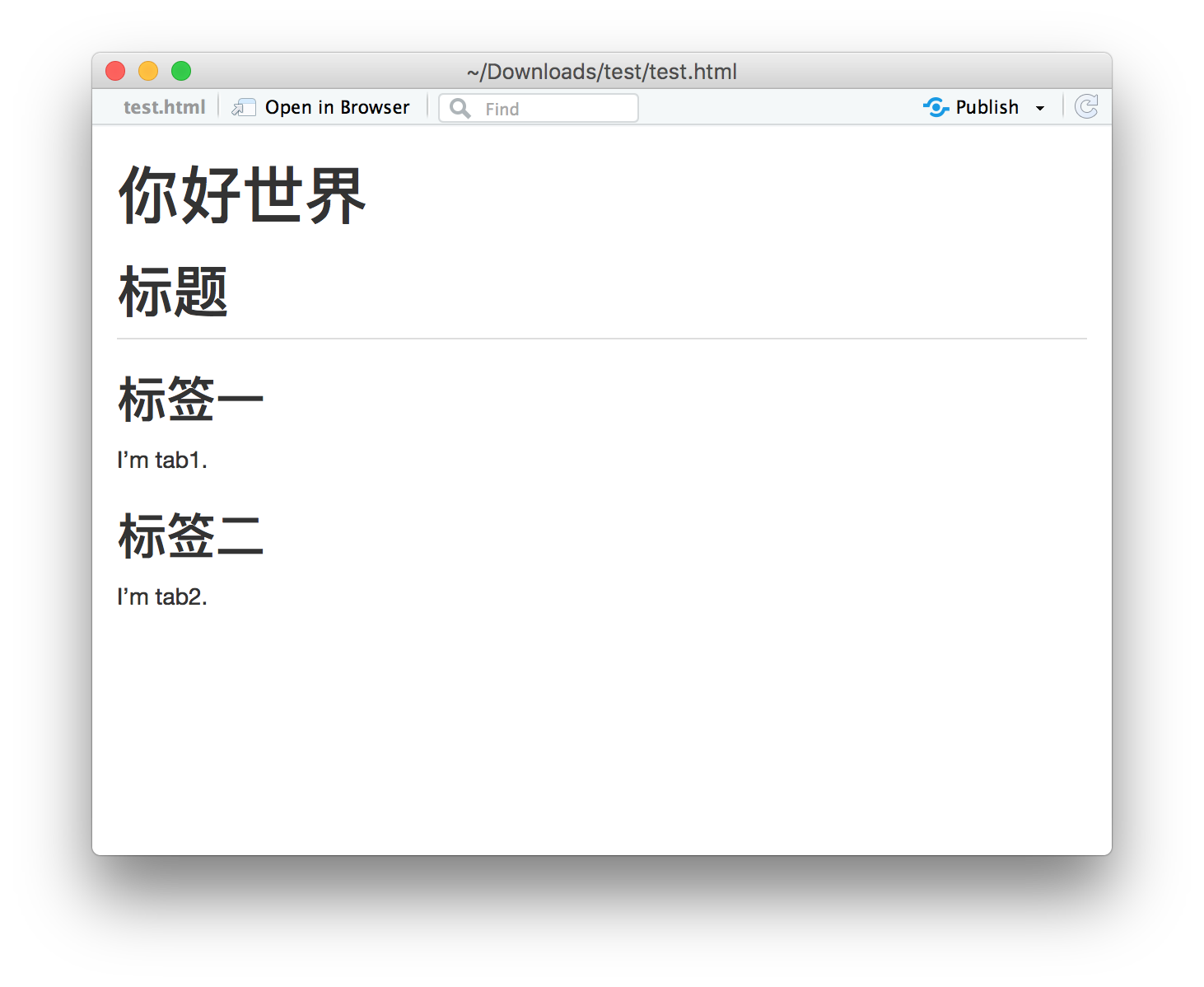
Solution 1
---
title: 你好世界
output: html_document
---
# 标题 {.tabset}
## 标签一 {#tab1}
I'm tab1.
## 标签二 {#tab2}
I'm tab2.
Solution 2
---
title: 你好世界
output:
html_document:
md_extensions: -ascii_identifiers
---
# 标题 {.tabset}
## 标签一
I'm tab1.
## 标签二
I'm tab2.